基因组选择(Genomic Selection, GS)是现代分子育种,尤其是精准育种体系(育种 4.0)的重要技术之一,成为加速遗传改良和培育优良品种的核心方法。然而,当前基因组预测模型仍面临两个关键挑战:一方面,基因组数据通常具有“高维小样本”特征,即SNP位点数量远超样本数量,容易导致模型过拟合和泛化能力下降;另一方面,大多数方法将SNP视为彼此独立的特征,忽略了染色体上标记之间的结构关联及位置信息,难以有效捕获复杂的遗传互作关系,从而制约了预测性能的进一步提高。同时,对个体间细粒度遗传变异及其表型异质性的建模能力仍然有限。
2026年5月,中国科学院遗传与发育生物学研究所降雨强研究组在生物信息学期刊
Briefings in Bioinformatics发表题为
CLCNet: a contrastive learning and chromosome-aware network for genomic prediction in plants的研究论文 (https://doi.org/10.1093/bib/bbag270)。该研究提出了一种新型深度学习框架CLCNet(Contrastive Learning and Chromosome-aware Network),将染色体结构感知机制与对比学习策略有机结合,用于作物基因组预测任务,在多个作物和性状上显著提升了预测性能。
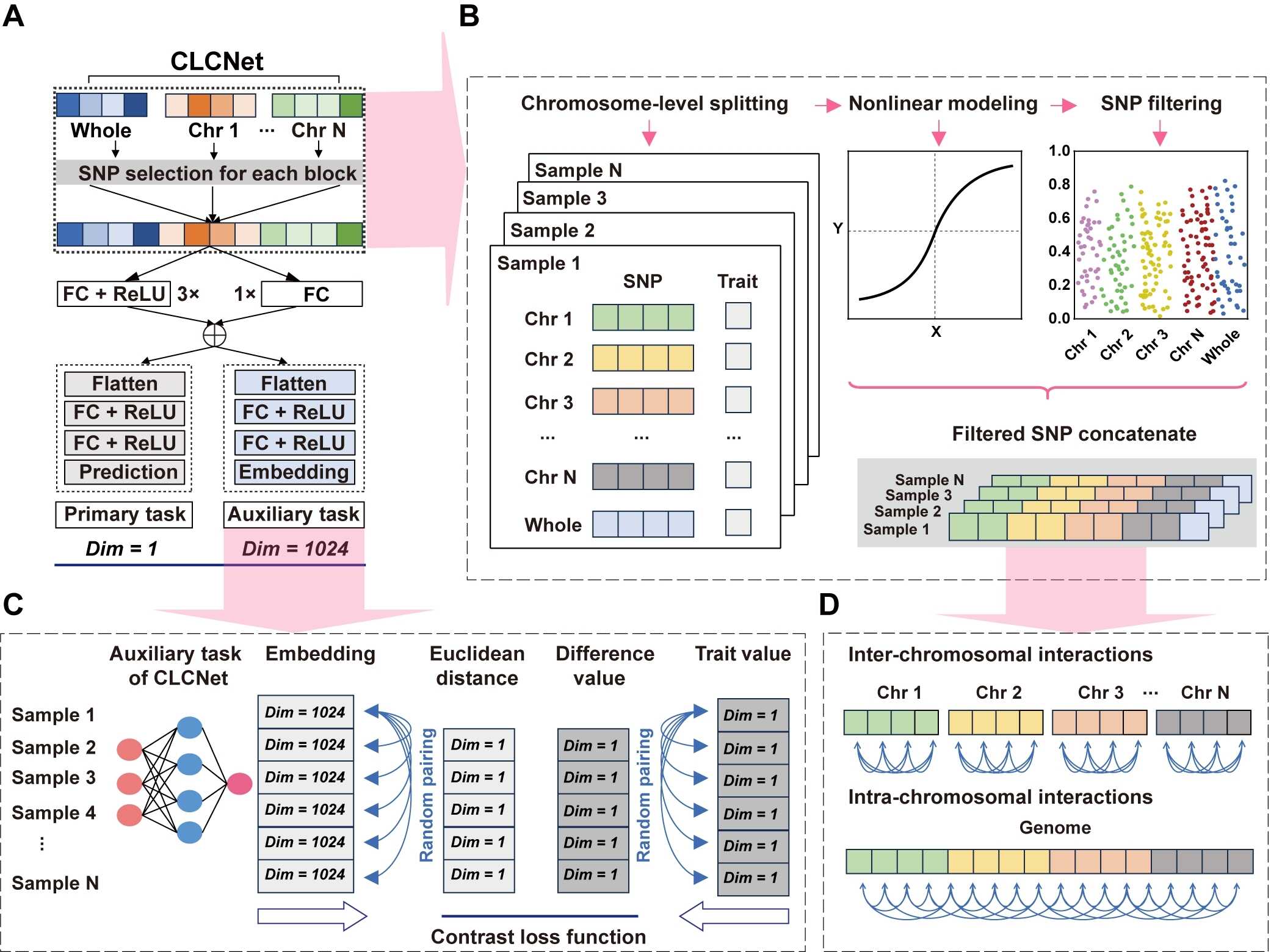
研究团队设计了“染色体感知模块(Chromosome-aware module)”,利用染色体层面的分块剪裁机制(Chromosome-level splitting)进行非线性建模与筛选(如图 1A/B 所示),既精准保留了局部的连锁不平衡(LD)结构,又兼顾了染色体内(Intra-chromosomal)与跨染色体间(Inter-chromosomal)的遗传关联,有效识别具有生物学意义的 SNP。利用对比学习(Contrastive Learning)策略,在每个训练批次内将样本两两随机配对(Random Pairing),使有限的样本生成丰富配对池,通过对比损失函数显式建模样本之间的基因型–表型差异(如图 1C 所示),使表型相似的样本在特征空间中更接近,而差异较大的样本则被有效区分,增强了模型对个体间细粒度遗传差异的捕捉能力。
研究人员在玉米、大豆、油菜和棉花等多种作物的10个关键农艺性状上进行了系统评估。结果表明,CLCNet在Pearson相关系数(PCC)和均方误差(MSE)等指标上表现最优,PCC提升幅度最高达 12.19%。在不同遗传结构的群体中,对于具有中等LD和较高遗传力(h²)的性状,CLCNet优势更加明显;而对于高LD、低遗传力性状,CLCNet依然保持稳定性能,未出现预测能力下降。此外,CLCNet还成功识别出多个与作物花期、分生组织发育及产量相关的已知关键基因,如玉米中的pebp3、knox3 和 bd1等,证明其在提升预测力的同时能够精准捕捉具有功能意义的遗传位点。该研究构建了一个兼具高精度、稳定性与生物学可解释性的作物基因组预测框架,为解决高维、小样本基因组数据建模难题提供了新思路,也为将生物学先验知识深度融入人工智能模型(AI for Science)建立了方法学范式。
遗传发育所在读博士生黄江伟(降雨强组)、杨智涵(梁承志组)为论文共同第一作者,降雨强研究员和韩荣成副研究员为共同通讯作者。梁承志、贺飞等研究组参与了该研究。该研究得到了国家重点研发计划等项目的资助。
CLCNet模型设计